Introduction: The Architecture Problem Healthcare Can’t Ignore
Healthcare IT systems are collapsing under their own weight. Not dramatically—there’s no spectacular crash—but through a slow, grinding accumulation of technical debt that makes even modest changes feel like performing surgery on a patient who’s wide awake.
Consider this scenario: A large hospital network wants to add a new patient portal feature that integrates wearable device data with their existing EHR. Simple enough, right? Except their EHR runs on a monolithic architecture built over fifteen years. The development team estimates nine months for implementation, not because the feature is complex, but because changing one component risks breaking dozens of others. Testing alone takes months. The deployment window? A nerve-wracking weekend where everyone holds their breath.
This isn’t an edge case. It’s the norm.
The promise of microservices architecture seems tailor-made for this problem. Decompose these monolithic beasts into smaller, independent services. Deploy updates without system-wide shutdowns. Scale components independently. Use the best tool for each job instead of being married to a single technology stack from 2008.
But here’s what the conference talks and vendor pitches often skip: microservices introduce their own category of complexity that can be particularly brutal in healthcare contexts. HIPAA compliance across dozens of services. Distributed transactions when patient safety depends on data consistency. Network latency when milliseconds matter in critical care scenarios.
This article cuts through the hype to examine microservices in healthcare cloud environments with the critical eye of someone who’s actually had to maintain these systems at 3 AM. We’ll explore real-world use cases where microservices shine, honest discussions of where they create more problems than they solve, and a practical framework for deciding when they’re the right choice for your healthcare system.
Understanding Microservices in the Healthcare Context
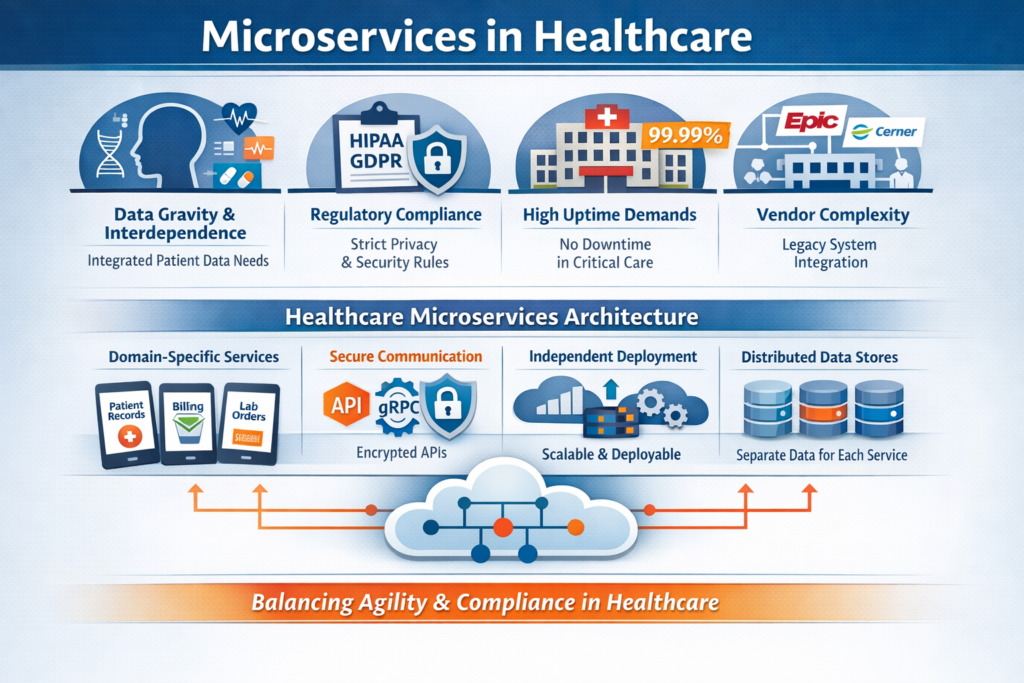
What Makes Healthcare Different
Before diving into microservices specifics, we need to acknowledge that healthcare isn’t just another industry with unique compliance requirements. Healthcare systems have architectural constraints that fundamentally affect how we build software:
Data gravity and interdependence: Patient data isn’t neatly compartmentalized. A single clinical decision might require lab results, medication history, imaging data, genetic information, and real-time vital signs. This interconnectedness makes the “loosely coupled” ideal of microservices harder to achieve.
Regulatory weight: HIPAA, HITECH, state privacy laws, and international regulations like GDPR create compliance overhead for every service boundary. Each API call between services carrying PHI (Protected Health Information) becomes a potential audit point and security vulnerability.
Uptime requirements: While every industry claims they need “five nines,” healthcare systems supporting critical care genuinely can’t afford downtime. The difference between 99.9% and 99.99% uptime isn’t academic—it’s measured in patient outcomes.
Vendor ecosystem complexity: Healthcare IT exists in a world of extensive vendor integration. Your microservices won’t operate in isolation—they’ll need to communicate with legacy systems from Epic, Cerner, Meditech, and dozens of specialized vendors who may or may not provide modern APIs.
Microservices: The Healthcare-Specific Definition
In healthcare cloud contexts, microservices architecture means decomposing healthcare applications into small, independently deployable services that:
- Own specific healthcare domains: Patient demographics, scheduling, clinical documentation, billing, pharmacy, lab orders—each becomes a separate service with its own database and business logic.
- Communicate via well-defined, secure APIs: RESTful APIs, gRPC, or message queues, all with healthcare-grade encryption, authentication, and audit logging baked in from day one.
- Can be developed, deployed, and scaled independently: The appointment scheduling service can be updated without touching the medication management service, and each can scale based on its own load patterns.
- Maintain their own data stores: Moving away from the single, massive database that every component touches—though in healthcare, this autonomy must be balanced against the need for data consistency in clinical contexts.
- Are built around healthcare business capabilities: Not just technical boundaries, but organized around how healthcare actually functions—admission/discharge/transfer, order entry, results reporting, clinical decision support.
The key insight: microservices in healthcare aren’t primarily about technology modernization. They’re about creating organizational and technical structures that can evolve at the pace healthcare demands while maintaining the safety and compliance the industry requires.
The Pros: Where Microservices Actually Deliver Value
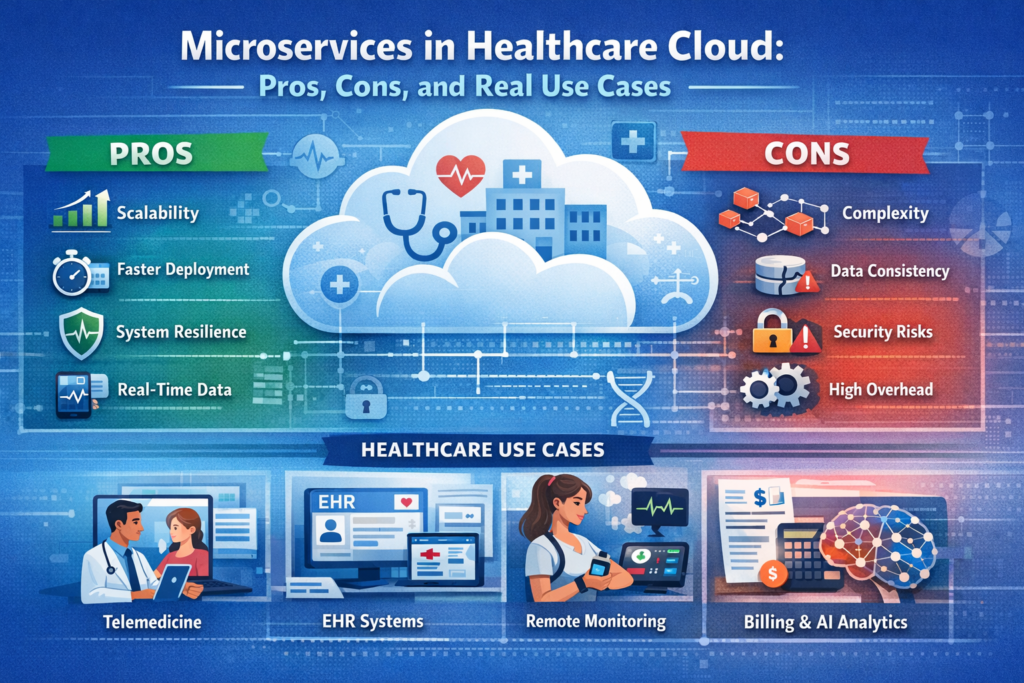
1. Independent Scaling for Wildly Different Load Patterns
Healthcare systems don’t scale uniformly. This is a critical characteristic that makes microservices particularly valuable.
The problem: A hospital’s patient portal might handle 10,000 concurrent users checking lab results during peak hours (8-10 AM), while the surgical scheduling system serves maybe 50 concurrent users. Their imaging service processes massive files but fewer requests. The billing system has monthly spikes around claim submission deadlines.
In a monolithic architecture, you scale everything together. You provision infrastructure for the portal’s peak load, which means the scheduling component has vastly more resources than it needs 95% of the time. Wasteful in commercial cloud environments where you’re paying by the hour.
The microservices solution: Each service scales based on its actual load patterns. During morning portal traffic spikes, Kubernetes automatically spins up additional pod replicas for the results-retrieval service while the scheduling service continues running on minimal resources. When the radiology department processes a batch of MRIs at 2 AM, the imaging service scales independently.
Real example: A telemedicine platform we analyzed handled 1,000 concurrent video sessions during peak COVID periods. Their video routing service needed to scale massively, but their prescription management service could run on a fraction of the infrastructure. By decomposing into microservices, they reduced cloud costs by 40% compared to scaling their previous monolithic application to handle peak video loads.
This isn’t theoretical optimization. It’s meaningful cost savings and better resource utilization in an industry where margins are constantly under pressure.
2. Technology Diversity Where It Actually Matters
The “polyglot” promise of microservices—using the right tool for each job—has particular relevance in healthcare’s diverse technical landscape.
AI/ML integration: Healthcare is rapidly adopting machine learning for diagnostic assistance, predictive analytics, and clinical decision support. These workloads have different requirements than traditional CRUD operations.
A Python-based microservice running TensorFlow models for analyzing radiology images can coexist with a Java-based EHR integration service and a Go-based real-time vital signs monitoring service. Each uses the technology stack that makes sense for its domain.
Real example: A hospital network built a sepsis prediction service as a microservice in Python using scikit-learn, while their main EHR integration layer remained in Java (connecting to Epic’s APIs). The ML models could be retrained and deployed independently, with data scientists working in familiar tools without needing to understand the Java codebase.
The sepsis service consumed real-time vitals, lab results, and patient history from other services, ran predictions every 15 minutes for ICU patients, and returned risk scores. When they needed to update the model based on new research, they could deploy changes to just that service without touching the critical EHR integration code.
Database diversity: Different healthcare data types have different storage needs. Microservices enable:
- Time-series databases (InfluxDB, TimescaleDB) for IoT device data and vital signs monitoring
- Document databases (MongoDB) for unstructured clinical notes with varying schemas
- Graph databases (Neo4j) for mapping patient relationship networks and disease correlation analysis
- Relational databases (PostgreSQL) for transactional systems like billing and scheduling
- Object storage (S3, Azure Blob) for medical imaging with metadata in separate databases
This isn’t about chasing shiny technologies. It’s about matching storage systems to data characteristics in ways that improve performance and reduce costs.
3. Fault Isolation in Life-Critical Systems
When your software supports patient care, failures need to be contained. Microservices architecture provides failure boundaries that can mean the difference between a minor service disruption and a system-wide outage.
The monolithic risk: In traditional architectures, a memory leak in the billing module can bring down the entire application, including critical clinical functions. A database deadlock caused by a reporting query can freeze order entry for medications.
Microservices containment: When the patient portal service crashes due to a bug in the lab results display logic, the medication administration recording service continues functioning normally. Nurses can still document medication administration. The crash is annoying for patients checking results, but it doesn’t impact direct patient care.
Real example: A hospital’s medication reconciliation service had a bug that caused it to enter an infinite loop when processing certain complex medication histories. In their previous monolithic architecture, this would have frozen the entire EHR interface.
As a microservice with proper resource limits and circuit breakers, the reconciliation service simply failed gracefully after hitting timeout thresholds. Clinicians received an error message for that specific function but could continue with other clinical documentation. The on-call team was alerted, fixed the bug, and deployed a new version of just that service—all while the rest of the system operated normally.
The key here is implementing proper resilience patterns: circuit breakers, bulkheads, timeouts, and graceful degradation. Without these, microservices can actually make cascading failures worse—more on that in the cons section.
4. Regulatory Compliance Boundaries
This advantage is underappreciated in general microservices discussions but critical in healthcare.
Different healthcare data types have different regulatory requirements. Microservices allow you to implement security controls proportionate to the sensitivity of the data each service handles.
Segmented compliance:
- De-identified research data services can have different access controls than services handling identifiable patient data
- Substance abuse treatment records (protected by 42 CFR Part 2) can be isolated in services with additional security layers
- Payment card data in billing services can meet PCI-DSS requirements without imposing those controls on clinical systems
- Genetic information (with GINA protections) can be handled by specialized services with appropriate safeguards
Audit efficiency: When an audit or security review is required, you can scope it to relevant services rather than auditing an entire monolithic codebase. When implementing a new security control or responding to a vulnerability, you can prioritize services based on data sensitivity.
Real example: A healthcare analytics company built separate microservices for their de-identified data pipeline and their services that occasionally processed identifiable data for authorized research. The de-identified services could be deployed to less expensive infrastructure without full HIPAA controls, while the PHI-handling services ran in a HIPAA-compliant environment with comprehensive audit logging, encryption at rest, and additional access controls.
This separation reduced their compliance costs and made security reviews more focused and efficient.
5. Organizational Velocity for Growing Teams
Conway’s Law states that organizations design systems that mirror their communication structures. In healthcare IT, where you might have teams focused on clinical systems, billing, patient engagement, and population health, microservices align technical boundaries with organizational boundaries.
Team autonomy: A patient portal team can iterate on user experience improvements without coordinating deployments with the EHR integration team. The telemedicine team can experiment with new video codecs without impacting the prescription management team’s work.
Reduced coordination overhead: In a well-designed microservices architecture, teams interact through API contracts rather than shared codebases. Changes within a service don’t require cross-team code reviews, as long as the API contract remains stable.
Real example: A digital health company with 80 developers organized into eight teams found that their deployment frequency increased from monthly releases of their monolithic application to an average of 15 deployments per day across all microservices. Teams could deploy improvements and bug fixes independently, dramatically reducing time-to-market for new features.
This velocity is particularly valuable in healthcare’s rapidly evolving landscape, where regulatory changes, new medical evidence, and competitive pressures demand quick adaptation.
The Cons: The Hidden Costs and Complexity
Now for the harder truths that often get glossed over in architecture discussions.
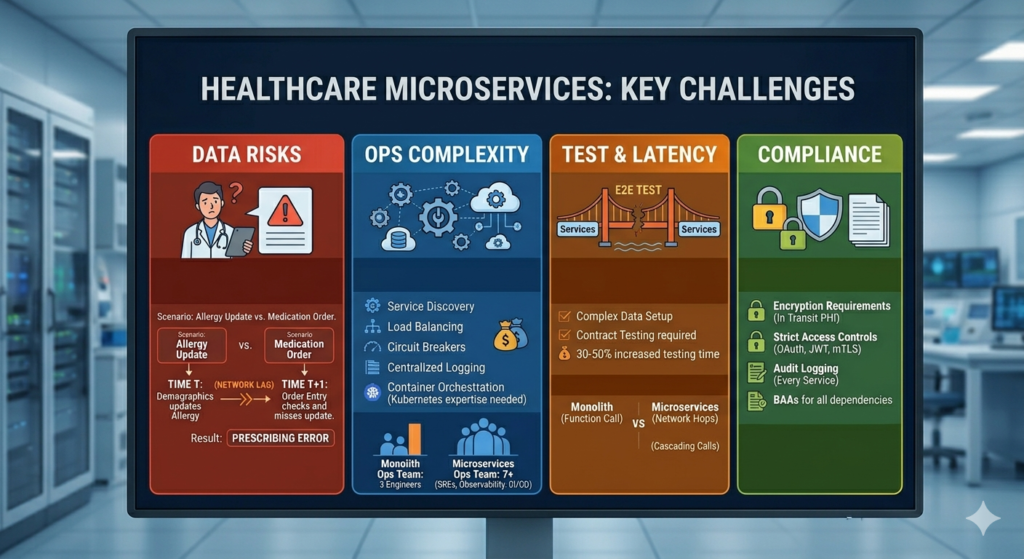
1. Distributed Systems Complexity in Life-Critical Contexts
Microservices transform a relatively straightforward programming model into a distributed systems problem. In healthcare, where correctness and reliability directly impact patient safety, this complexity is magnified.
Network is unreliable: Every API call between services is a potential failure point. In a monolithic application, a function call either succeeds or throws an exception—it’s deterministic. In microservices, a network call might:
- Succeed
- Fail immediately
- Timeout (did it actually fail, or is the network just slow?)
- Succeed but the response gets lost in transit
- Partially succeed (the remote service processed the request but crashed before sending a response)
Healthcare implications: Consider a medication order flow that involves multiple services:
- Order entry service validates the order
- Drug interaction service checks for contraindications
- Pharmacy service queues the medication
- Billing service creates a charge
In a monolithic system, this is a single database transaction. Either all steps succeed or none do. In microservices, you’re dealing with distributed transactions, which are notoriously difficult to implement correctly.
Real problem: A hospital implemented their pharmacy system as microservices. A network glitch caused a timeout between the order entry service and the pharmacy service. The order entry service showed an error to the clinician, who re-submitted the order. Due to race conditions and retry logic, the pharmacy service actually received both orders. A patient nearly received a double dose before a pharmacist caught the discrepancy.
This isn’t a theoretical edge case. It happened. The fix required implementing idempotency keys, proper timeout handling, and distributed transaction patterns like Saga. All complexity that didn’t exist in their previous monolithic system.
2. Data Consistency Challenges in Clinical Workflows
Healthcare workflows often require strong consistency guarantees that are at odds with microservices’ principle of independent data stores.
The ACID vs. BASE tradeoff: Traditional databases provide ACID guarantees (Atomicity, Consistency, Isolation, Durability). Distributed microservices typically operate with BASE (Basically Available, Soft state, Eventually consistent).
“Eventually consistent” is fine for social media feeds. It’s potentially dangerous in healthcare.
Real scenario: A patient’s allergy information is updated in the demographics service while a clinician in the order entry service is prescribing a medication. Due to eventual consistency and caching, the order entry service doesn’t see the allergy update. The drug interaction check passes. The medication order proceeds.
The painful solutions:
- Distributed transactions: Implement two-phase commit or Saga patterns, which add significant complexity and can create deadlocks.
- Event sourcing: Store all changes as events and rebuild state from event logs. Powerful but requires a fundamental rethinking of how you build applications, and debugging production issues becomes significantly harder.
- Careful service boundary design: This is the pragmatic approach—design service boundaries to minimize scenarios requiring strong consistency across services. Keep tightly coupled data within single services.
Real example: A hospital system initially decomposed their EHR into microservices with separate services for patient demographics, allergies, medications, and problems lists. They quickly discovered that clinicians needed these data elements to be synchronized in real-time for safe care decisions.
Their eventual solution: They merged these into a single “Core Clinical Data” service that maintained strong consistency for this critical subset of data, while keeping truly independent services (scheduling, billing, patient portal) separate. This was the right architectural compromise, but it meant abandoning some of the fine-grained decomposition they’d originally envisioned.
3. Operational Complexity and the DevOps Tax
Microservices don’t just distribute your application—they distribute your operational complexity across tens or hundreds of moving parts.
What you’re now responsible for:
- Service discovery: How services find each other in dynamic cloud environments
- Load balancing: Distributing requests across service instances
- Circuit breakers: Preventing cascading failures
- Distributed tracing: Following a single user request across 15 service hops to debug a performance issue
- Centralized logging: Aggregating logs from dozens of services to troubleshoot a problem
- Secrets management: Distributing and rotating credentials across all services
- Service mesh complexity: Managing tools like Istio or Linkerd that add another layer of infrastructure
- Container orchestration: Kubernetes expertise becomes mandatory, and Kubernetes is not simple
The team requirement: You need engineers who understand distributed systems, networking, container orchestration, and observability tooling. These skills are expensive and in short supply. Many healthcare organizations struggle to find this talent.
Real cost example: A mid-sized healthcare SaaS company migrated from a monolithic application (managed by 3 operations engineers) to a microservices architecture. They eventually needed:
- 2 dedicated SREs for Kubernetes cluster management
- 1 engineer focused on observability tooling (Prometheus, Grafana, Jaeger)
- 1 engineer managing CI/CD pipelines across 40+ services
- Additional on-call rotations because now there were more things to break at 3 AM
The total operational headcount increased from 3 to 7, not because the application did anything fundamentally different, but because of architectural complexity.
4. Testing Becomes a Distributed Systems Problem
Testing microservices is significantly harder than testing monolithic applications, and in healthcare, where software errors can impact patient safety, this is a serious concern.
Integration testing complexity: Testing a single feature might require spinning up 8 different services, each with its own database, and ensuring they’re all configured correctly. Local development environments become complex multi-container Docker Compose setups that consume significant resources and are fragile.
End-to-end testing: A complete user workflow might touch 15 services. Creating automated tests that exercise this entire path requires sophisticated test infrastructure and is prone to flakiness (tests that fail intermittently due to timing issues, not actual bugs).
Data setup challenges: Each service has its own database. Setting up test data for integration tests means coordinating state across multiple databases. This is tedious and error-prone.
Real problem: A telemedicine platform had a critical bug that only manifested when specific sequences of operations occurred across their video service, prescription service, and EHR integration service. The bug was reproducible in production but took days to replicate in test environments because coordinating the exact state across all three services’ databases was extremely difficult.
Contract testing: Tools like Pact help with consumer-driven contract testing, but they require discipline and add another layer of testing infrastructure to maintain.
The time cost: Teams report that moving to microservices often increases the time required to write and maintain tests by 30-50%. In healthcare, where regulatory requirements already demand extensive testing, this is a significant burden.
5. Performance Overhead and Latency Concerns
Every service boundary introduces network latency. In healthcare scenarios where real-time data is critical, this overhead is not trivial.
The latency math: A function call in a monolithic application: ~0.01 milliseconds. A REST API call to another service: ~50-100 milliseconds. If a single user action triggers a cascade of service calls, latency accumulates.
Real scenario: A critical care dashboard aggregates data from:
- Vital signs monitoring service
- Lab results service
- Medication administration service
- Ventilator settings service
- Imaging service
In a monolithic architecture, this might be a complex database query taking 200ms. In microservices, with sequential service calls:
- 80ms for vital signs
- 120ms for lab results
- 60ms for medications
- 90ms for ventilator data
- 150ms for imaging metadata
Total: 500ms, and that’s assuming nothing goes wrong. If you need to make parallel calls to mitigate this, you’re introducing additional complexity in error handling and aggregation logic.
The network cost: Serializing data to JSON, transmitting over HTTP, deserializing on the other end—this has CPU and memory costs that a function call doesn’t have. At scale, this can meaningfully increase infrastructure costs.
Healthcare-specific concern: In critical care scenarios, clinicians need data immediately. A 2-second delay in displaying current vital signs because of service communication overhead is unacceptable when every second matters in a code blue situation.
6. The HIPAA Compliance Multiplication Problem
Every service boundary is a potential HIPAA violation point. More services mean more:
Encryption requirements: Each service-to-service communication carrying PHI requires encryption in transit. Managing TLS certificates across dozens of services is operationally complex.
Access controls: Every service needs authentication and authorization mechanisms. You’re implementing OAuth, JWT token validation, or mutual TLS authentication dozens of times. Each implementation is a potential security vulnerability.
Audit logging: Every service that touches PHI needs comprehensive audit logs tracking who accessed what data when. Aggregating and analyzing these logs across many services requires sophisticated tooling.
Business Associate Agreements (BAAs): If you’re using third-party services (managed databases, message queues, observability tools), each one that might touch PHI requires a BAA. More services often means more third-party dependencies.
Real example: A healthcare analytics company’s security audit revealed that 3 of their 25 microservices were inadvertently logging full patient records to their centralized logging system (ELK stack). Because logs were considered debugging data, they weren’t encrypted at rest and had less strict access controls than production databases.
The remediation required:
- Implementing log scrubbing to remove PHI
- Encrypting log storage
- Restricting access to log data
- Retroactively purging historical logs containing PHI
- Additional training for all developers
This happened because more services meant more places to make mistakes.
7. Versioning and Breaking Changes
When multiple services depend on each other, managing API versions and coordinating changes becomes a significant challenge.
The backward compatibility burden: In a monolithic application, you can refactor interfaces and update all callers in a single deployment. In microservices, changing an API means either:
- Maintaining multiple API versions simultaneously (operational overhead)
- Coordinating deployments across multiple services (losing the independence that was a key benefit)
- Breaking clients (unacceptable in production healthcare systems)
Real problem: A hospital’s appointment scheduling service needed to add a new required field to its booking API (insurance authorization number, due to changing billing requirements). They had 7 other services that called this API.
Their options:
- Deploy a new API version (/v2/) and maintain both versions while all consumers migrated (they maintained both versions for 9 months)
- Add the field as optional initially, give all teams time to update their code, then make it required (took 4 months and required careful coordination)
- Use an API gateway to transform old requests to the new format (added complexity and a potential performance bottleneck)
All of these options were painful. The equivalent change in their old monolithic system would have been a single coordinated deployment.
Real Healthcare Use Cases: When Microservices Make Sense
Let’s examine specific healthcare scenarios where microservices architecture provides genuine value, based on actual implementations.
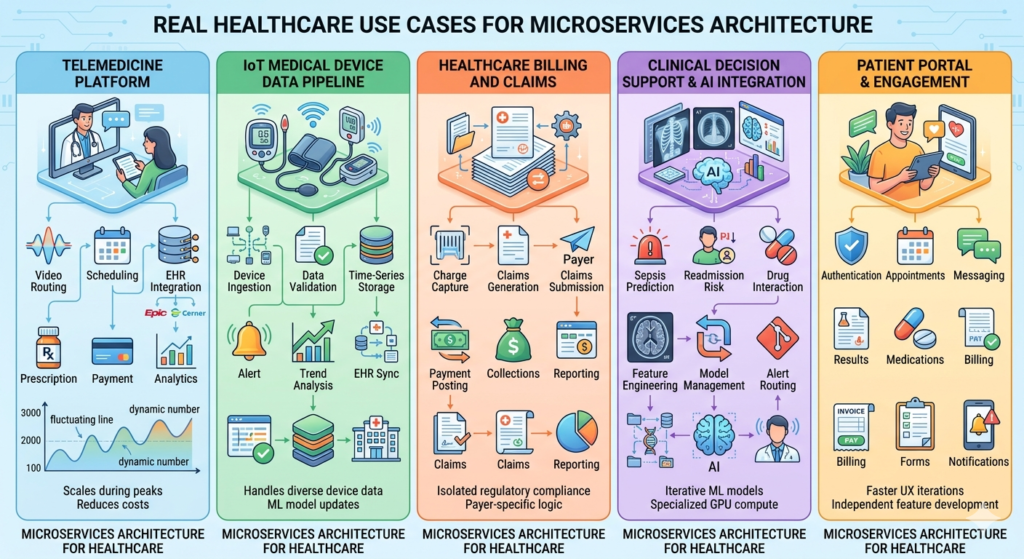
Use Case 1: Telemedicine Platform with Elastic Demand
The scenario: A telemedicine platform experiencing massive demand fluctuations—100 concurrent sessions during normal hours, 3,000 during evening peak times, with additional spikes during flu season and (obviously) during the COVID-19 pandemic.
Why microservices worked:
The platform decomposed into distinct services:
- Video routing service: Handled WebRTC connections, required low latency, scaled horizontally during peak demand
- Scheduling service: Relatively stable load, didn’t need to scale with video sessions
- EHR integration service: Connected to various EHR systems (Epic, Cerner, Athenahealth), needed specialized retry logic and vendor-specific handling
- Prescription service: Integrated with e-prescribing systems, had strict uptime requirements but moderate load
- Payment processing service: PCI-DSS compliant, needed to be isolated for compliance
- Analytics service: Batch processing, could run on cheaper spot instances during off-peak hours
The concrete benefits:
- Cost optimization: The video routing service scaled with demand using Kubernetes Horizontal Pod Autoscaler, while other services ran on minimal infrastructure. This reduced infrastructure costs by 40% compared to scaling the entire monolithic application for peak video load.
- Technology fit: The video routing service was written in Go for performance and low latency. The EHR integration service was in Python to leverage existing healthcare integration libraries. The analytics service used Spark for batch processing.
- Independent deployment: During the pandemic, they needed to rapidly iterate on video quality and connection resilience. The video team deployed updates multiple times per day without coordinating with other teams.
The challenges they faced:
- Session state management: Coordinating data across services during a video visit was complex. They implemented event-driven architecture with Kafka but faced eventual consistency challenges.
- Testing complexity: End-to-end testing of a complete visit flow required all services running, making local development challenging.
- Observability overhead: Debugging issues that spanned multiple services required sophisticated distributed tracing (they used Jaeger).
Verdict: The architectural complexity was worth it. The extreme scaling requirements and need for rapid iteration in the video components would have been impossible with a monolithic architecture.
Use Case 2: IoT Medical Device Data Pipeline
The scenario: A remote patient monitoring platform collecting data from home health devices—glucose monitors, blood pressure cuffs, pulse oximeters, weight scales—for chronic disease management.
Why microservices worked:
The data pipeline consisted of specialized services:
- Device ingestion service: Received data from thousands of devices using various protocols (MQTT, HTTPS, proprietary protocols)
- Data validation service: Applied device-specific validation rules and flagged anomalous readings
- Time-series storage service: Wrote validated data to InfluxDB optimized for time-series queries
- Alert service: Monitored for readings outside parameters and notified care teams
- Trend analysis service: ML-based service that identified concerning patterns over time
- EHR sync service: Periodically pushed summary data to patients’ EHRs
The concrete benefits:
- Technology specialization: Time-series database (InfluxDB) for device data, PostgreSQL for patient metadata, Redis for caching recent readings. Each service used the optimal storage technology.
- Scaling by data type: During morning hours, blood pressure and weight readings spiked (patients measuring after waking up). The ingestion service auto-scaled for this pattern, while other services maintained steady resource levels.
- ML model iteration: The trend analysis service could be updated independently as data scientists improved prediction models. New models were deployed without touching the critical data ingestion pipeline.
- Fault isolation: When the EHR sync service had bugs, device data continued to be collected and processed. Patients and care teams could still view readings even when EHR integration was broken.
The challenges they faced:
- Data consistency: Ensuring the alert service saw validated data without race conditions required careful event ordering and idempotency.
- Device heterogeneity: Each device type needed specific handling. They eventually had device-specific ingestion handlers as plugins to the main ingestion service, adding deployment complexity.
- Debugging patient-reported issues: When a patient reported missing data, tracing it through the pipeline required checking logs from 5 different services and correlating timestamps across distributed systems.
Verdict: Strong use case for microservices. The different scaling patterns, technology requirements, and the need to iterate on ML models independently made the complexity worthwhile.
Use Case 3: Healthcare Billing and Claims Processing
The scenario: A medical billing platform processing insurance claims, patient statements, and payment posting for a network of clinics.
Why microservices worked:
Billing has distinct sub-domains with different characteristics:
- Charge capture service: Received charges from EHR systems
- Claims generation service: Created insurance claims in various formats (837i, 837p, proprietary formats)
- Claims submission service: Sent claims to clearinghouses and payers
- Remittance processing service: Processed ERAs (Electronic Remittance Advice) and EOBs (Explanation of Benefits)
- Payment posting service: Applied payments to patient accounts
- Collections service: Managed patient billing and payment plans
- Reporting service: Generated financial reports for practices
The concrete benefits:
- Regulatory isolation: PCI-DSS requirements for payment processing were isolated to the payment posting service, reducing compliance scope for other components.
- Payer-specific logic: Each insurance payer has unique requirements. The claims generation service could be updated for specific payers without risk to other billing functions.
- Batch processing patterns: The claims submission service had peak loads at month-end when practices rushed to submit claims. It could scale independently and use more cost-effective infrastructure than real-time services.
- Independent vendor integration: When integrating with a new clearinghouse, only the claims submission service needed changes. The rest of the billing platform was unaffected.
The challenges they faced:
- Distributed transactions: A claim involves data from multiple services. Ensuring consistency when a claim was corrected and resubmitted required complex saga patterns.
- Revenue cycle visibility: Finance teams needed comprehensive reports showing charges, claims, and payments. Aggregating this data across services required building a separate data warehouse.
- Reconciliation complexity: Matching payments to charges across service boundaries was more complex than in their previous monolithic system where everything was in one database.
Verdict: Moderate success. The regulatory isolation and payer-specific customization benefits were real, but the distributed transaction complexity for core billing workflows was painful. A hybrid approach with billing core functions in a single service and peripheral functions (reporting, collections) as separate services might have been more optimal.
Use Case 4: Clinical Decision Support and AI Integration
The scenario: A health system implementing AI-driven clinical decision support—sepsis prediction, readmission risk, drug interaction checking, and diagnostic assistance for radiology.
Why microservices worked:
Each AI model became a separate service:
- Sepsis prediction service: Python-based, TensorFlow model, processed vital signs and lab results every 15 minutes for ICU patients
- Readmission risk service: Ran daily batch predictions on recently discharged patients
- Drug interaction service: Real-time API called during medication ordering
- Radiology AI service: Processed chest X-rays for pneumonia detection
Plus supporting services:
5. Feature engineering service: Prepared data for ML models from raw EHR data
6. Model management service: Tracked model versions, performance metrics, and coordinated deployments
7. Alert routing service: Delivered AI predictions to clinicians through appropriate channels
The concrete benefits:
- Model lifecycle independence: Data scientists could retrain and deploy the sepsis model without affecting other AI services. Model updates happened weekly based on new data.
- Technology heterogeneity: Different models used different frameworks (TensorFlow, scikit-learn, PyTorch) and had vastly different infrastructure needs. The radiology service needed GPU instances; the drug interaction service didn’t.
- Scaling patterns: The drug interaction service needed real-time response with high concurrency. The readmission risk service ran batch predictions overnight. Each could use appropriately sized infrastructure.
- A/B testing: New model versions could be deployed and compared against existing models by routing a percentage of requests to the new version. This was straightforward with service-level routing.
The challenges they faced:
- Feature consistency: Ensuring the feature engineering service prepared data consistently for all models required careful schema management and versioning.
- Model performance monitoring: Detecting when a model’s predictions degraded required aggregating metrics across services and correlating with actual patient outcomes.
- Data freshness: Some predictions required very recent data. Managing caching and data synchronization across services to ensure models had current information was complex.
Verdict: Excellent use case for microservices. The different technology stacks, infrastructure needs, deployment cadences, and the ability to iterate on models independently provided clear value that outweighed the complexity.
Use Case 5: Patient Portal and Engagement Platform
The scenario: A patient-facing application providing appointment scheduling, lab results viewing, medication refills, messaging with providers, and bill payment.
Why microservices worked:
The portal decomposed by functional area:
- Authentication service: Handled patient login, MFA, and session management
- Appointments service: Calendar viewing and scheduling
- Messaging service: Secure patient-provider communication
- Results service: Lab and imaging results viewing
- Medications service: Medication list and refill requests
- Billing service: Statement viewing and payment processing
- Forms service: Questionnaires and intake forms
- Notifications service: Email, SMS, and push notifications
The concrete benefits:
- User experience iteration: The front-end team could rapidly improve the appointments UI and deploy changes without coordinating with teams working on billing or results.
- Mobile vs. web: The messaging service API served both web and mobile applications. The API evolved independently of the front-end implementations.
- Load patterns: The results service had traffic spikes around typical lab result release times (mornings). The appointments service had different peak times. Each scaled independently.
- Third-party integration: The notifications service integrated with Twilio and SendGrid. Updates to notification logic didn’t impact other portal functions.
The challenges they faced:
- Session management: Coordinating authentication state across services required a shared session service and careful token validation in each service.
- Performance overhead: Loading the patient dashboard required calling 8 different services. They implemented a BFF (Backend for Frontend) pattern to aggregate data, which added complexity.
- Consistent UX: Ensuring error messages, loading states, and design patterns were consistent across features owned by different teams required design system discipline beyond technical architecture.
Verdict: Mixed results. The portal benefits from some decomposition, but very fine-grained services created integration overhead. A better approach might have been 3-4 larger services (clinical data, scheduling, communication, billing) rather than 8 smaller ones.
Decision Framework: When to Use (and Avoid) Microservices
Here’s a practical framework for deciding whether microservices make sense for your healthcare system, based on real-world factors rather than architectural idealism.
Strong Indicators for Microservices
1. Genuinely different scaling requirements
Not just “some components are more active,” but meaningful differences. If one component needs to scale 10x during peak hours while others are stable, microservices can provide real cost savings and performance benefits.
Questions to ask:
- Do we have components with 5x+ differences in load patterns?
- Would scaling the entire application for peak loads waste significant resources?
- Are we constrained by infrastructure costs due to over-provisioning?
2. Multiple teams working on distinct features
If you have 5+ development teams working on clearly separable features (e.g., one team on billing, another on patient portal, another on clinical documentation), microservices align with organizational boundaries and reduce coordination overhead.
Questions to ask:
- Do teams frequently block each other waiting for deployments?
- Are we experiencing merge conflicts and integration pain in our monolithic codebase?
- Do teams work on features that rarely interact at the code level?
3. Heterogeneous technology requirements
When different components genuinely benefit from different technology stacks—ML models in Python, real-time processing in Go, traditional business logic in Java—microservices enable using the right tool for each job.
Questions to ask:
- Do we have components that would significantly benefit from different languages or frameworks?
- Are we trying to force all problems into a single technology stack despite poor fit?
- Do we have specialized teams with deep expertise in specific technologies?
4. Regulatory isolation needs
When you need to isolate PCI-DSS compliance for payment processing, or 42 CFR Part 2 protections for substance abuse records, or have different security requirements for different data types.
Questions to ask:
- Can we reduce compliance scope by isolating specific functions?
- Do different components handle data with different regulatory requirements?
- Would isolation reduce our audit and compliance costs?
5. Different change velocities
If some components need daily deployments (patient-facing features) while others change monthly (EHR integrations), microservices allow different deployment cadences.
Questions to ask:
- Are we slowing down rapid iteration in some areas to ensure stability in others?
- Do we have features that need continuous deployment alongside stable components?
- Is our current release process too slow for business needs in specific areas?
Strong Indicators Against Microservices
1. Small team (< 10 engineers)
The operational overhead of microservices requires dedicated resources. Small teams are better served by well-structured monoliths.
Reality check:
- Do we have dedicated operations/SRE capacity?
- Can we afford 24/7 on-call rotations for multiple services?
- Do we have Kubernetes and distributed systems expertise?
2. Tightly coupled workflows requiring strong consistency
When business processes require ACID transactions across what would be multiple services, forcing service boundaries creates distributed transaction nightmares.
Reality check:
- Do our workflows require real-time consistency across multiple data domains?
- Are we in healthcare contexts where eventual consistency is unsafe?
- Would most of our API calls be synchronous dependencies between services?
3. Early-stage product with unclear boundaries
If you’re still figuring out your domain model and what features you’ll offer, premature service decomposition leads to constant refactoring of service boundaries.
Reality check:
- Is our domain model stable, or are we still experimenting?
- Are we still discovering what our core entities and workflows are?
- Would we need to reorganize services frequently as we learn?
4. Limited operational maturity
Microservices require sophisticated monitoring, logging, tracing, and deployment infrastructure. Without this maturity, you’ll spend more time fighting infrastructure than delivering features.
Reality check:
- Do we have centralized logging and monitoring?
- Do we have automated deployment pipelines?
- Can we effectively debug distributed systems issues?
- Do we have established incident response processes?
5. Performance-critical, latency-sensitive use cases
If you’re building real-time clinical monitoring where every millisecond matters, network overhead between services can be unacceptable.
Reality check:
- Do we have sub-100ms latency requirements?
- Would service-to-service communication introduce unacceptable delays?
- Are we optimizing for minimum possible latency?
The Hybrid Middle Ground (Often the Right Answer)
Many successful healthcare systems don’t choose purely monolithic or microservices—they choose strategic decomposition:
Modular monolith with selective extraction:
- Build a well-structured monolith with clear internal module boundaries
- Extract specific high-value components as microservices (e.g., AI services, patient-facing mobile APIs, high-scale components)
- Keep core clinical workflows in the monolith where strong consistency matters
Example structure:
- Core clinical monolith: Patient demographics, encounters, clinical documentation, orders—things that require transactional consistency
- Separate microservices: Patient portal API, analytics/reporting, billing integration, ML services, notification service
This approach provides some microservices benefits (independent scaling for portal traffic, technology choices for ML, isolation for compliance) while avoiding distributed transaction complexity for core clinical workflows.
Migration Strategy: If You’re Moving from Monolith to Microservices
If you’ve decided microservices are appropriate, don’t do a big-bang rewrite. Incremental migration reduces risk:
1. Start with the periphery
Extract services that have clear boundaries and minimal dependencies first:
- Notification services (email, SMS)
- Reporting and analytics (read-only, can tolerate eventual consistency)
- Batch processing jobs
- New features that don’t yet exist in the monolith
2. Use the strangler pattern
Gradually route traffic to new services while keeping the monolith operational:
- Put an API gateway in front of the monolith
- Implement new features as microservices
- Gradually extract pieces of the monolith behind the gateway
- Decommission monolith components only when fully replaced
3. Establish operational foundations first
Before extracting your first service, ensure you have:
- Centralized logging (ELK, Splunk, CloudWatch)
- Distributed tracing (Jaeger, Zipkin)
- Metrics and monitoring (Prometheus, Grafana)
- Automated CI/CD pipelines
- Service mesh or API gateway
- Secrets management solution
Extracting services before these foundations are in place creates operational chaos.
4. Define your service boundaries based on business capabilities, not technical layers
Bad decomposition (technical layers):
- Database service
- Business logic service
- API service
Good decomposition (business capabilities):
- Appointment scheduling service (owns scheduling data and logic)
- Patient demographics service (owns patient data and logic)
- Billing service (owns charges, claims, payments)
Each service should own both the data and the business logic for its domain.
Practical Implementation Considerations
If you’re moving forward with microservices in healthcare, here are critical implementation details often overlooked in high-level architecture discussions.
API Design for Healthcare Microservices
Use FHIR standards where applicable: The Fast Healthcare Interoperability Resources (FHIR) standard provides well-defined resource models for healthcare data. Using FHIR-compliant APIs for patient data, appointments, observations, and other clinical resources provides:
- Standardized data models reducing custom schema design
- Built-in support in healthcare integration tools
- Easier future integration with external systems
However, FHIR isn’t always the answer. Internal APIs between your services might be more efficient with custom, purpose-built schemas. Reserve FHIR for boundaries where interoperability matters.
Versioning strategy: Implement URL-based versioning (/v1/appointments, /v2/appointments) from day one. Healthcare systems often need to maintain old API versions for extended periods due to vendor integration timelines.
Idempotency for safety: Healthcare APIs should support idempotency keys to prevent duplicate operations. A retry of a medication order should not create duplicate orders.
Security Architecture
Service-to-service authentication: Implement mutual TLS (mTLS) or OAuth2 client credentials flow for service-to-service communication. Don’t rely on network perimeter security alone.
Centralized identity and access management: Use a dedicated IAM service rather than each service implementing its own authentication. Options include:
- Cloud provider solutions (AWS IAM, Azure AD)
- Open-source: Keycloak, Auth0
- Service mesh with built-in identity: Istio with SPIFFE/SPIRE
API gateway for external access: Don’t expose internal services directly. Use an API gateway to:
- Terminate TLS
- Authenticate external requests
- Rate limit and throttle
- Provide a stable external API even as internal services evolve
Data Management Patterns
Database per service—with exceptions: The ideal is each service owns its data store. The reality in healthcare: some data needs to be shared.
Pragmatic approach:
- Core clinical data that requires strong consistency: shared database or single service
- Independent domains: separate databases
- Read-only views: Consider creating read replicas or data projection services
Event-driven architecture for data synchronization: When services need to react to changes in other services, use event-driven patterns:
- Service A publishes events to a message bus (Kafka, RabbitMQ, AWS SNS/SQS)
- Service B subscribes to relevant events
- Loosely coupled, asynchronous communication
Example: When a patient’s allergy information is updated in the demographics service, it publishes a “PatientAllergiesUpdated” event. The clinical decision support service subscribes to this event and invalidates its cache.
CQRS for complex read requirements: When services need to query data owned by multiple other services, implement Command Query Responsibility Segregation:
- Commands (writes) go to individual services
- Queries (reads) go to a separate read model that aggregates data from multiple services
- The read model is eventually consistent but optimized for complex queries
Observability and Debugging
Distributed tracing is non-negotiable: Implement distributed tracing from the start using:
- OpenTelemetry (vendor-neutral)
- Jaeger
- AWS X-Ray
- Google Cloud Trace
Tag every trace with patient identifiers (de-identified or encrypted) and request IDs so you can follow a single request across all service hops.
Centralized logging with correlation IDs: Every log entry should include:
- Correlation ID (unique per request, passed across services)
- Service name and version
- Timestamp (synchronized across services—use NTP)
- Appropriate context without logging PHI
Metrics that matter:
- Service-level metrics: Request rate, error rate, latency (RED method)
- Business-level metrics: Appointment bookings, prescription orders, login successes
- Infrastructure metrics: CPU, memory, disk, network
Don’t just monitor technical health—monitor whether the system is actually serving its healthcare purpose.
Health checks and readiness probes: Every service should implement:
/healthendpoint: Is the service alive?/readyendpoint: Is the service ready to receive traffic? (database connected, dependencies available)
Kubernetes uses these for automated recovery and load balancing decisions.
Resilience Patterns
Circuit breakers: Prevent cascading failures by stopping calls to failing services. If the lab results service is down, the circuit breaker prevents the patient portal from timing out on every request—it fails fast and shows a helpful error message.
Timeouts and retries: Set aggressive timeouts for all service calls (start with 5 seconds, tune based on observed latency). Implement exponential backoff for retries with jitter to prevent thundering herd problems.
Bulkheads: Isolate resources so one failing component doesn’t exhaust resources for the entire service. Use separate thread pools or connection pools for different dependencies.
Graceful degradation: Define what reduced functionality looks like. If the drug interaction service is unavailable, can medication orders still proceed with a warning to the clinician to manually check interactions?
Conclusion: Architectural Pragmatism in Healthcare Technology
Microservices are not a silver bullet for healthcare IT’s challenges, nor are they an inherently flawed approach destined to create complexity. They’re a tool—powerful when applied to the right problems, counterproductive when forced into the wrong contexts.
The healthcare organizations succeeding with microservices share common traits:
They start with clear problems, not architectures. They don’t adopt microservices because it’s the modern approach. They adopt them because they have genuine scaling challenges, organizational structures that demand team autonomy, or technology heterogeneity that a monolithic architecture can’t accommodate.
They invest in operational capabilities before decomposing applications. They build robust CI/CD pipelines, implement comprehensive observability, and develop distributed systems expertise before their first service extraction. They understand that microservices shift complexity from application code to operational infrastructure.
They make strategic, not universal, choices. They don’t decompose everything. They keep tightly coupled clinical workflows in monolithic services where ACID transactions matter, while extracting peripheral services where independence provides value. They resist the temptation to over-engineer simple problems.
They respect healthcare’s unique constraints. They understand that eventual consistency isn’t always acceptable when patient safety is at stake. They build defense-in-depth security because every service boundary is a potential HIPAA violation. They design for reliability because downtime can impact patient care.
The future of healthcare IT isn’t a binary choice between monoliths and microservices. It’s thoughtfully designed systems that use appropriate architectures for different components, that balance agility with reliability, and that ultimately serve the goal of better patient care.
For RizeX Labs and our clients in healthcare technology, this means approaching architecture decisions with rigorous analysis rather than trend-following. It means asking hard questions about organizational readiness, operational capabilities, and genuine technical requirements. It means being willing to say “not yet” or “not everything” when microservices aren’t the right fit.
The most important architectural decision isn’t choosing microservices or monoliths. It’s building systems that can evolve as healthcare demands change, maintain the reliability that patient care requires, and enable the engineering teams to deliver value without drowning in complexity.
That’s the real promise of modern architecture patterns—not perfect systems, but evolvable ones. In healthcare technology’s rapidly changing landscape, evolvability might be the most valuable architectural quality of all.
About RizeX Labs
At RizeX Labs, we specialize in delivering advanced Salesforce and cloud-based solutions, helping organizations modernize their digital infrastructure. Our expertise spans microservices architecture, healthcare cloud platforms, and scalable system design.
We help healthcare providers move from rigid, monolithic systems to flexible, cloud-native architectures that improve performance, compliance, and patient outcomes.
Internal Links:
- Salesforce Admin & Development Training
- Remote Patient Monitoring (RPM) in Salesforce Health Cloud: Transforming Connected Healthcare Delivery
- How to Use AI in Salesforce Health Cloud for Predictive Patient Care (Einstein + Real Use Cases)
- New Releases in Salesforce Health Cloud Spring ’26: What Healthcare Organizations Need to Know
- How to Customize Salesforce Health Cloud Using Lightning Web Components (LWC) for Healthcare Use Cases
- 30 Essential Questions About Salesforce Health Cloud Answered: Beginner to Advanced Guide
- Salesforce Sales Cloud vs Health Cloud: The Strategic CRM Decision That Defines Your Healthcare Business Trajectory
- Using Salesforce Health Cloud for Insurance & Claims Coordination: Beyond the Hospital Walls
External Links:
- Salesforce Official Website
- Salesforce Health Cloud Overview
- Salesforce Revenue Cloud Overview
- Salesforce AppExchange (CLM tools)
- Salesforce CPQ Documentation
Quick Summary
Microservices architecture in healthcare cloud environments offers genuine benefits—independent scaling for components with different load patterns (reducing costs by 30-40%), technology diversity for AI/ML integration, fault isolation for safer systems, and team autonomy for faster feature delivery—but introduces serious complexity that's particularly challenging in healthcare contexts. Every service boundary multiplies HIPAA compliance touchpoints, creates distributed transaction problems where strong data consistency is critical for patient safety, adds 50-100ms network latency per service call, and requires 2-3x operational headcount with expertise in Kubernetes, distributed tracing, and service mesh technologies. Success cases include telemedicine platforms with elastic demand, IoT device pipelines with heterogeneous data, and AI services requiring independent deployment, while failures occur when forcing microservices onto tightly coupled clinical workflows, small teams (<15 engineers), or latency-sensitive critical care systems. The pragmatic approach isn't choosing microservices versus monoliths universally, but strategic decomposition: keeping core clinical workflows requiring ACID transactions in well-structured monoliths while extracting peripheral services (patient portals, analytics, notifications, ML models) where independence provides measurable value—ultimately prioritizing evolvable systems that serve patient care over architectural ideology.

