Introduction: The End of Single-Channel AI Assistants
For years, AI assistants operated in silos. A chatbot handled text. A phone IVR handled voice. A human agent handled anything involving a photo, screenshot, or document. Customers were forced to switch channels, repeat themselves, and tolerate handoffs that introduced friction, delays, and frustration at every turn.
The era of single-channel AI is ending. Agentforce Multimodal agents ushers in a fundamentally different paradigm — one where a single intelligent agent can receive a spoken question, analyze an uploaded image, and respond with a text summary, all within one continuous, context-aware conversation. This isn’t a collection of separate AI tools stitched together. It’s a unified intelligence that understands the world the way humans experience it: through multiple senses, simultaneously.
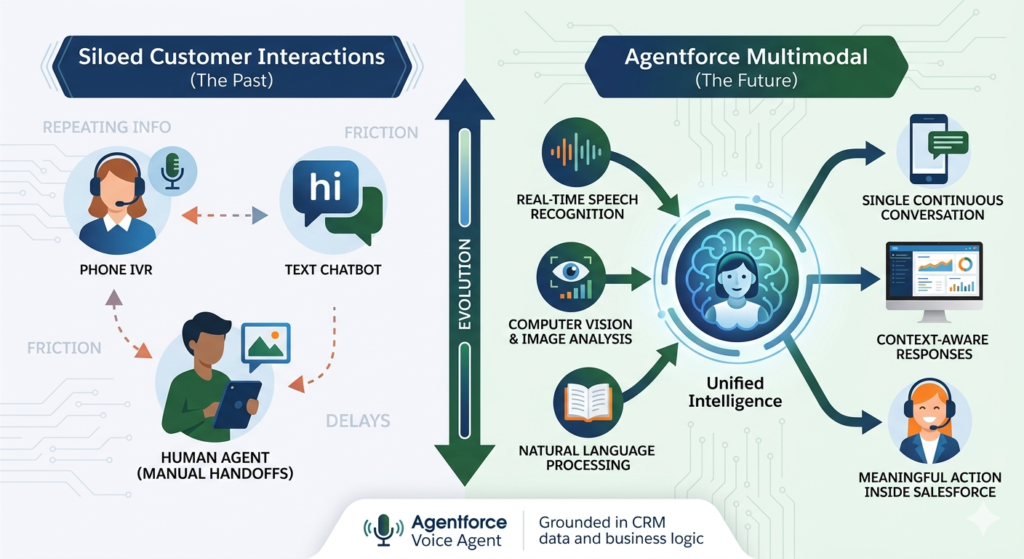
Salesforce multimodal AI combines natural language processing, real-time speech recognition, and computer vision into one orchestrated system, grounded in your CRM data and business logic. The result is an agent that doesn’t just answer questions — it understands context, interprets visual information, listens to spoken requests, and takes meaningful action inside Salesforce.
Central to this capability is the Agentforce Voice Agent, which enables real-time, natural voice conversations between customers and AI — with automatic transcription, intent detection, CRM lookups, and spoken responses that feel genuinely human. When voice is combined with image understanding and text-based chat, organizations can deliver experiences that meet customers exactly where they are, in the format most natural to them.
This guide explores every dimension of Agentforce Multimodal — what it is, how it works, how to set it up, and why it represents the most important evolution in Salesforce AI to date.
What Is Agentforce Multimodal?
Agentforce Multimodal is the capability within the Salesforce Agentforce platform that enables a single AI agent to process and respond across three distinct input and output modalities: text, voice, and images.
Rather than deploying separate AI tools for each channel — a chatbot for web, a voice bot for phone, a human review process for images — Agentforce Multimodal consolidates all three into one intelligent agent that maintains context across every interaction type.
What a Multimodal Agent Can Process
Text Conversations
The agent reads and responds to typed messages across web chat, messaging platforms, email threads, and internal copilot interfaces. It understands natural language, follows conversational context, and executes CRM actions based on what users write.
Voice Interactions
Through the Agentforce Voice Agent capability, the system listens to spoken input in real time, transcribes it accurately, detects the user’s intent, and responds with natural spoken language — all while performing backend CRM lookups and actions simultaneously.
Image Uploads and Visual Context
Users can submit photos, screenshots, documents, receipts, or any visual input. The agent analyzes the image content, extracts relevant information, and incorporates visual context into its understanding of the conversation — without requiring a human to interpret the image manually.
Salesforce multimodal AI unifies these three channels into one continuous conversational experience. A customer can start a conversation by typing, switch to voice when it’s more convenient, and upload an image to provide visual context — and the agent retains full awareness of everything that has happened across all three modalities throughout the session.
This unified intelligence is what distinguishes agentforce multimodal from conventional omnichannel approaches, which route different inputs to different systems and lose context in the process.
Why Multimodal AI Matters for Modern Businesses
The business case for agentforce multimodal isn’t abstract — it’s grounded in how customers and employees actually want to work.
Customers Want to Interact on Their Own Terms
Some customers prefer typing. Others find voice more natural, especially on mobile. Many need to share a screenshot or photo to accurately describe their problem. When AI agents only support one modality, organizations force customers to adapt to technology rather than letting technology adapt to customers. Multimodal AI eliminates this friction entirely.
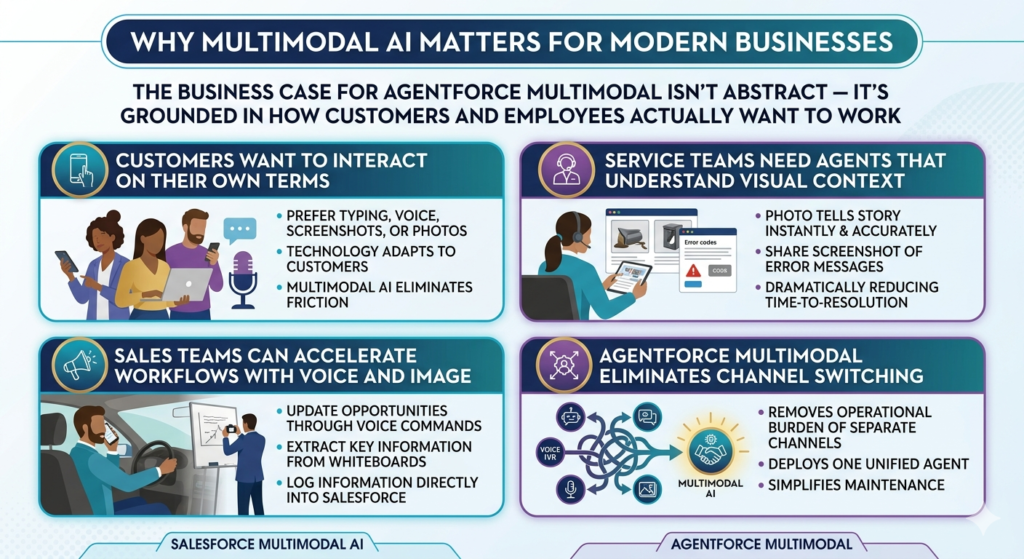
Service Teams Need Agents That Understand Visual Context
A customer calling about a damaged product delivery can describe the damage in words, but a photo tells the story instantly and accurately. A customer confused by an error message can share a screenshot rather than reading out an alphanumeric error code. Salesforce multimodal AI enables service agents — human and AI alike — to understand visual context as part of the conversation, dramatically reducing time-to-resolution.
Sales Teams Can Accelerate Workflows With Voice and Image
A sales rep driving between appointments can update an opportunity, log a call note, or request account information through voice commands — hands-free and without touching a screen. Another rep can photograph a whiteboard from a discovery session and have the AI extract and log the key information directly into Salesforce.
Agentforce Multimodal Eliminates Channel Switching
Perhaps most importantly, agentforce multimodal removes the operational burden of managing separate channel experiences. Instead of maintaining a chatbot, a voice IVR, and a manual image review process as three separate systems with three separate maintenance requirements, organizations deploy one unified agent that handles all three.
Core Capabilities of Salesforce Multimodal AI
Salesforce multimodal AI is built on a set of interconnected core capabilities that work together to create genuinely intelligent, context-aware agent interactions.
Natural Language Understanding
At the foundation is Einstein’s large language model infrastructure, which interprets user intent from text input with high accuracy. The model understands nuance, handles ambiguity, follows multi-turn conversations, and grounds its understanding in CRM-specific context — knowing who the customer is, what products they own, and what their service history looks like.
Speech-to-Text and Text-to-Speech
Real-time speech processing converts spoken input into text that the AI can process, and converts AI-generated text responses into natural-sounding spoken output. Salesforce multimodal AI uses high-accuracy speech recognition models tuned for customer service conversations, minimizing transcription errors even in noisy environments.
Image Recognition and Analysis
Computer vision models analyze uploaded images to identify objects, read text, detect damage, interpret documents, and extract structured information from unstructured visual content. The system can recognize product photos, interpret screenshots, process forms, and analyze receipts — returning structured data that the agent can act upon.
Context Retention Across Modalities
One of the most technically significant aspects of agentforce multimodal is its ability to maintain conversational context across modality switches. When a customer transitions from text to voice, or from voice to image upload, the agent doesn’t lose track of what has already been discussed. The full interaction history — regardless of which modality it occurred in — informs every subsequent response.
CRM Data Grounding
Every agent response is grounded in real Salesforce data. Whether the agent is responding to a voice question about account status, analyzing an image of a damaged product, or answering a text question about order history, its responses are informed by live CRM records, service cases, product catalogs, and knowledge articles.
Secure Action Execution
Salesforce multimodal AI doesn’t just answer questions — it takes action. The agent can create cases, update records, process refunds, schedule appointments, escalate to human agents, and trigger workflows — all through secure, permission-controlled execution that respects your Salesforce org’s security model.
How Agentforce Voice Agent Works
The Agentforce Voice Agent is the voice-enabled component of the Agentforce Multimodal platform, designed to deliver natural, real-time voice conversations between customers and AI without the robotic, scripted feel of traditional IVR systems.
Real-Time Voice Conversations
When a customer calls a voice-enabled Agentforce channel, the Agentforce Voice Agent engages immediately — no hold music, no menu trees. The agent listens to natural speech, processes it in real time, and responds within seconds. The experience is designed to feel like speaking with a knowledgeable human agent, not navigating a phone tree.
Automatic Transcription
As the customer speaks, the Agentforce Voice Agent transcribes their words in real time using high-accuracy speech-to-text models. Transcriptions are available for review, compliance logging, and quality monitoring — giving supervisors full visibility into voice interactions without listening to call recordings.
Intent Detection
Beyond transcription, the Agentforce Voice Agent identifies what the customer is trying to accomplish. Is this a billing question? A product return? A technical support issue? Intent detection routes the conversation to the appropriate response strategy and triggers relevant CRM lookups and knowledge retrieval automatically.
CRM Lookups and Actions
Once intent is identified, the Agentforce Voice Agent queries Salesforce in real time — retrieving account information, case history, order status, or product details — and incorporates that data into its spoken response. If the customer wants to update their shipping address, create a support case, or check their subscription status, the agent executes those actions directly in Salesforce during the conversation.
Spoken Responses
The agent responds in natural-sounding speech generated by text-to-speech models. Responses are dynamically generated based on CRM data and conversation context — not pre-recorded scripts — meaning every spoken response is accurate, relevant, and personalized to the specific customer and situation.
Image Understanding in Agentforce Multimodal
Visual inputs represent one of the most powerful and underutilized dimensions of customer service and sales workflows. Agentforce multimodal extends AI understanding beyond words and into the visual world, enabling agents to analyze images as a natural part of the conversation.
Product Photos
When a customer uploads a photo of a product — whether to ask about compatibility, report damage, or request a return — the agent analyzes the image, identifies the product, assesses visible conditions, and responds with accurate, contextually relevant information. No human review required.
Screenshots
Error messages, software UI confusion, and account display issues are among the most common customer service requests — and they’re notoriously difficult to communicate through text alone. Agentforce multimodal enables customers to simply screenshot their screen and upload it. The agent reads the error message, identifies the issue, and provides step-by-step resolution guidance.
Documents and Forms
Insurance forms, rental agreements, application documents, and government IDs can be submitted as images. The agent extracts relevant fields — names, dates, amounts, policy numbers — and populates CRM records automatically, eliminating manual data entry.
Receipts and Purchase Verification
For returns, warranty claims, and expense verification, customers can upload receipt photos. The agent reads the receipt, verifies the purchase against CRM records, and initiates the appropriate process — all within the same conversation.
Error Messages and Technical Diagnostics
Field technicians and IT support professionals can photograph equipment error codes, network diagrams, or physical damage. The agentforce multimodal agent analyzes the image, cross-references relevant knowledge articles, and provides diagnostic guidance — dramatically reducing time-to-resolution for complex technical issues.
Text-Based Interactions and Chat Automation
While voice and image capabilities represent exciting new frontiers, text remains the highest-volume interaction modality for most organizations. Agentforce Multimodal delivers sophisticated text-based experiences across every channel where customers and employees communicate in writing.
Web Chat
Agentforce deploys as a web chat widget on any customer-facing webpage, handling inbound inquiries with natural language understanding, CRM grounding, and action execution. The same agent that handles voice calls and image uploads responds to web chat messages — maintaining consistent persona, capabilities, and context.
Messaging Apps
Through Salesforce’s messaging integrations, agentforce multimodal extends to SMS, WhatsApp, Facebook Messenger, and other messaging platforms. Customers can submit images through these channels as well, enabling multimodal interactions through the apps they already use.
Internal Copilots
Employees benefit from agentforce multimodal as an internal copilot — an AI assistant accessible within Salesforce that responds to typed questions, voice commands, or uploaded documents to surface relevant CRM data, draft communications, update records, and automate routine tasks.
Knowledge Retrieval
The agent retrieves and surfaces relevant knowledge articles, FAQs, product documentation, and policy information in response to customer queries — across all modalities. A customer who asks a voice question receives a spoken summary; one who asks via chat receives a formatted text response with links.
Workflow Automation
Text conversations can trigger complex backend workflows — case creation, approval processes, record updates, notification sending, and system integrations — all initiated by natural language requests without any manual intervention.
Real-World Use Cases for Agentforce Multimodal
The practical impact of agentforce multimodal becomes clearest through real-world scenarios where combining text, voice, and image transforms what would otherwise be a frustrating, multi-step process into a seamless, single-interaction resolution.
Use Case 1: Customer Service — Screenshot Plus Voice
A software customer is experiencing an error that prevents them from logging in. They call the support line, where the Agentforce Voice Agent answers immediately. While describing their problem verbally, the agent suggests they also upload a screenshot through the companion chat interface. The customer shares the screenshot, the agent reads the error code in the image, cross-references the knowledge base, and delivers a step-by-step solution through both spoken guidance and a text summary — all without human escalation.
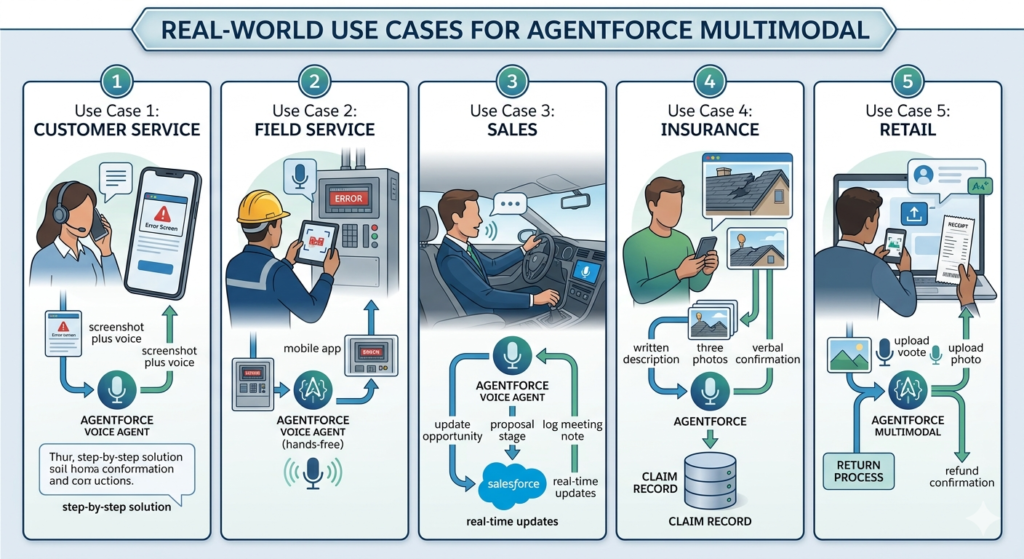
Use Case 2: Field Service — Equipment Photo Troubleshooting
A field technician arrives at a job site to service industrial equipment displaying an unfamiliar error code. Rather than calling technical support and waiting on hold, the technician photographs the equipment panel and uploads it to Agentforce through the mobile app. The agent identifies the equipment model from the image, reads the error code, retrieves the relevant diagnostic procedure from the knowledge base, and walks the technician through the resolution process via voice — hands-free.
Use Case 3: Sales — Voice-Driven CRM Updates
A sales rep finishing a customer meeting jumps into their car and uses the Agentforce Voice Agent to update their Salesforce opportunity: “Move the Acme Corp deal to Proposal stage, set close date to end of next month, and log a meeting note.” The agent executes all three updates in real time through voice commands alone — no screen touching required.
Use Case 4: Insurance — Claim Submission With Photo and Text
An insurance policyholder experiences storm damage to their home. Through the insurer’s Agentforce-powered portal, they submit a written description of the damage, upload three photos of affected areas, and speak their verbal confirmation of the claim details through the Agentforce Voice Agent. The agent analyzes the photos for damage assessment, extracts relevant information from the description, creates a new claim record in Salesforce, assigns it to the appropriate adjuster, and confirms the submission in both text and voice.
Use Case 5: Retail — Product Return With Receipt Image
A retail customer wants to return a product purchased online. They initiate a chat, upload a photo of their receipt, and speak their reason for the return through the voice interface. The agentforce multimodal agent reads the receipt, validates the purchase against the order record in Salesforce, confirms return eligibility, and initiates the return process — issuing a refund confirmation without any human agent involvement.
Architecture of Salesforce Multimodal AI
Understanding how Salesforce multimodal AI works at the architectural level helps organizations plan implementations, assess integration requirements, and set realistic performance expectations.
Agentforce Orchestration Layer
At the top of the architecture sits the Agentforce orchestration engine — the “brain” that coordinates inputs and outputs across all modalities, routes user requests to the appropriate processing models, manages conversation context, and triggers actions within Salesforce. Every text message, voice input, and image upload passes through this orchestration layer.
Einstein AI Models
Einstein’s large language models handle natural language understanding and generation — interpreting user intent from text or transcribed voice, generating contextually relevant responses, and grounding outputs in CRM data. These models are continuously updated by Salesforce and benefit from the platform’s scale across millions of customer interactions.
Speech Services
Real-time speech-to-text and text-to-speech processing powers the Agentforce Voice Agent capability. These services operate with low latency to ensure voice conversations feel natural and responsive, with accuracy tuned specifically for business and customer service vocabularies.
Image Processing Models
Computer vision models handle image analysis — object recognition, text extraction (OCR), damage detection, and document parsing. These models are integrated into the Agentforce orchestration layer so image analysis results are immediately available as context for the agent’s next response.
Data Cloud Grounding
Salesforce Data Cloud provides the unified customer data foundation that grounds every agent response in real-time, accurate customer context. Rather than relying on static CRM snapshots, Salesforce multimodal AI agents access live unified profiles that reflect the most current customer interactions, preferences, and history across all channels.
CRM Workflows and Actions
The final architectural layer is action execution — the agent’s ability to create, read, update, and trigger workflows within Salesforce in response to customer requests. This layer is secured through Salesforce’s standard permission model, ensuring agents can only take actions appropriate to their configured scope.
Key Benefits of Agentforce Multimodal
Organizations that implement agentforce multimodal report benefits that span customer experience, operational efficiency, and business performance.
Faster Issue Resolution
When customers can share both verbal descriptions and visual evidence simultaneously, agents — AI or human — resolve issues faster. Eliminating the back-and-forth of text-only troubleshooting reduces average handle time and increases first-contact resolution rates.
Better Customer Experiences
Meeting customers in their preferred modality — whether that’s typing, speaking, or sharing images — creates interactions that feel effortless and human. The result is higher customer satisfaction scores and stronger brand loyalty.
Reduced Manual Effort
Automated image analysis, voice transcription, and CRM action execution eliminate enormous amounts of manual work. Customer service teams handle more complex, high-value interactions while AI handles routine multimodal requests autonomously.
More Accurate Understanding
Combining text, voice, and image context gives the AI a richer, more complete understanding of what customers need than any single modality can provide. Misunderstandings decrease. Accuracy increases.
Higher Automation Rates
Agentforce multimodal enables automation of customer interactions that previously required human review — particularly those involving visual content. Insurance claims, product returns, technical troubleshooting, and document processing can all be automated through multimodal AI at scale.
Setup Guide for Agentforce Multimodal
Implementing agentforce multimodal requires careful configuration across several Salesforce platform components. Follow these steps to enable and optimize your multimodal agent.
Step 1: Configure Agentforce
- Navigate to Setup → search for Agentforce
- Enable the Agentforce feature for your org
- Configure your Agent persona — name, tone, and scope of capabilities
- Define the Topics your agent will handle (service, sales, HR, etc.)
- Set Guardrails to control what the agent can and cannot do
Step 2: Connect Voice Channels
- In Agentforce Setup, navigate to Voice Channel Configuration
- Connect your telephony provider through Salesforce’s supported integrations (Service Cloud Voice)
- Configure call routing rules to direct inbound calls to the Agentforce Voice Agent
- Set fallback escalation rules for calls the AI cannot resolve
- Test the voice channel connection with a sample inbound call
Step 3: Enable Image Input Support
- Navigate to Agentforce Channel Settings
- Enable File and Image Upload for web chat and messaging channels
- Define accepted file types (JPEG, PNG, PDF, etc.) and maximum file sizes
- Configure image processing actions — which Einstein vision models to apply
- Set content moderation rules for uploaded images
Step 4: Define Prompts and Actions
- In Agent Builder, create modality-specific prompt templates for text, voice, and image scenarios
- Define Actions the agent can execute — case creation, record updates, knowledge retrieval, escalation
- Configure image analysis actions — what to do when a product photo, screenshot, or document is received
- Set voice response formatting — ensure spoken responses are concise and natural-sounding (avoid bullet points and formatting in voice outputs)
Step 5: Ground Responses With CRM and Knowledge
- Connect your agent to Salesforce Knowledge for knowledge article retrieval
- Enable Data Cloud integration for real-time customer profile grounding
- Configure object permissions — which CRM objects the agent can read and write
- Set up Einstein Search Answers to retrieve relevant knowledge content across all modalities
Step 6: Test Multimodal Scenarios
- Use Agent Testing in Agentforce Builder to simulate text conversations
- Make test calls to your voice channel and evaluate response accuracy and latency
- Upload sample images — product photos, screenshots, documents — and verify the agent’s analysis accuracy
- Test modality switching — start a text conversation, transition to voice, upload an image, and confirm context retention throughout
Step 7: Monitor Performance
- Enable Agentforce Analytics to track resolution rates, escalation rates, and customer satisfaction by modality
- Set up voice transcription review dashboards for quality monitoring
- Monitor image analysis accuracy and flag common misclassification patterns
- Review conversation logs regularly to identify prompt improvements and edge cases
Best Practices for Agentforce Multimodal Deployments
Design Modality-Specific Prompts
A response that works perfectly in text — with bullet points, headers, and links — is awkward when spoken aloud. Design separate prompt templates for voice responses that use natural conversational language, shorter sentences, and verbal transitions instead of visual formatting.
Set Image Validation Rules
Define clear rules for what the agent should do when image quality is too low to analyze accurately. Build in a graceful fallback: “I can see you’ve shared an image, but the quality makes it difficult to read. Could you try uploading a clearer photo?” This prevents the agent from guessing incorrectly.
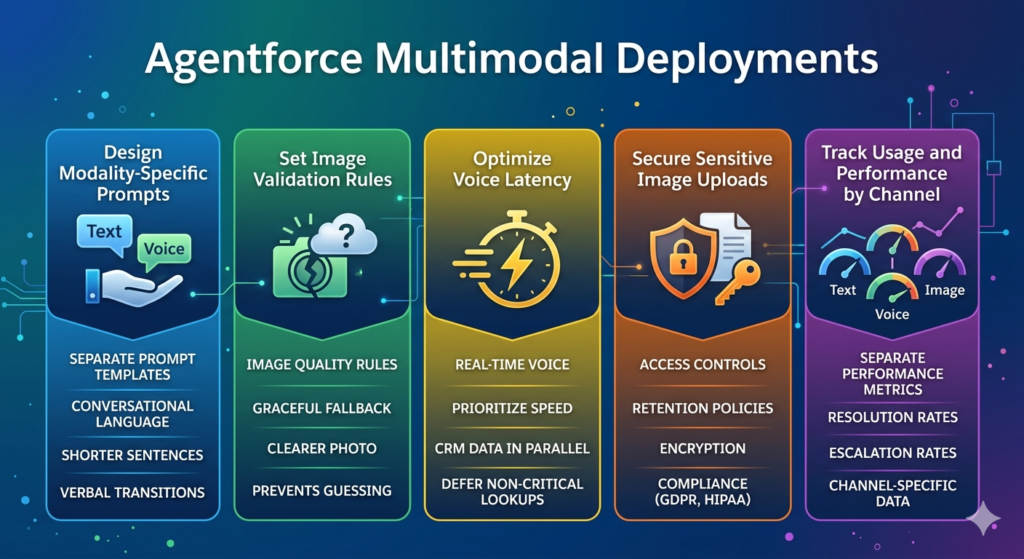
Optimize Voice Latency
Real-time voice conversations require responses within 1–2 seconds to feel natural. Optimize your agent’s action sequences to prioritize speed — retrieve essential CRM data in parallel rather than sequentially, and defer non-critical lookups to after the initial response is delivered.
Secure Sensitive Image Uploads
Images submitted by customers may contain sensitive information — medical records, financial documents, government IDs. Implement strict access controls, retention policies, and encryption for image uploads. Ensure compliance with GDPR, HIPAA, and other relevant regulations before enabling image inputs in regulated industries.
Track Usage and Performance by Channel
Maintain separate performance metrics for text, voice, and image interactions. Resolution rates, escalation rates, and customer satisfaction scores may differ significantly across modalities — and you need channel-specific data to optimize each one effectively.
Common Challenges and Solutions
Challenge 1: Poor Image Quality
Problem: Customers upload blurry, dark, or poorly framed images that the vision models cannot accurately analyze.
Solution: Implement real-time image quality validation that assesses resolution and clarity before processing. Provide customers with guidance on how to take useful photos, and build graceful fallback prompts that request a better image without making the customer feel criticized.
Challenge 2: Background Noise in Voice Calls
Problem: Customers calling from noisy environments — cars, public spaces, open offices — produce audio that reduces transcription accuracy and intent detection reliability.
Solution: Enable noise cancellation processing in your voice channel configuration. Train your voice agent with varied acoustic conditions. Build confirmation steps into high-stakes voice actions (“I heard you’d like to process a return for order 12345. Is that correct?”) to catch transcription errors before executing irreversible actions.
Challenge 3: Context Switching Issues
Problem: When customers switch between text, voice, and image within one session, the agent loses track of earlier conversation context.
Solution: Ensure your Agentforce configuration maintains a unified conversation state object that persists across modality switches. Test modality transition scenarios thoroughly during QA. Build explicit context summaries into your agent’s transition logic (“Based on what you’ve described and the image you shared…”).
Challenge 4: Compliance and Privacy Concerns
Problem: Voice recordings and image uploads may be subject to strict data privacy regulations, creating compliance risk if not handled properly.
Solution: Implement clear customer disclosure and consent mechanisms before voice recording begins. Establish data retention and deletion policies for voice transcriptions and image files. Work with your legal team to ensure compliance with applicable regulations before enabling multimodal inputs in sensitive industries.
Challenge 5: Escalation Handling
Problem: Multimodal conversations that escalate to human agents lose context when the handoff occurs, forcing customers to repeat themselves.
Solution: Configure Agentforce to pass the complete conversation transcript — including image thumbnails, voice transcription text, and interaction history — to the receiving human agent’s screen. Invest in agent workspace design that makes multimodal context immediately visible to the human taking over the interaction.
Agentforce Multimodal vs. Traditional Chatbots: A Direct Comparison
| Dimension | Traditional Chatbot | Agentforce Multimodal |
|---|---|---|
| Supported Inputs | Text only; rigid keyword matching | Text, voice, and images in one unified session |
| Customer Experience | Frustrating; forces channel switching for complex issues | Natural and fluid; customers choose their preferred modality |
| Context Awareness | Limited to current session text; loses context between channels | Full context retention across all modalities within one session |
| CRM Integration | Basic; often requires API development | Native Salesforce integration with real-time data access and action execution |
| Image Handling | Not supported; requires human review | Built-in image analysis with automatic extraction and action triggering |
| Voice Capability | Not supported or through separate IVR system | Real-time natural voice conversations through Agentforce Voice Agent |
| Automation Capability | Low; handles simple FAQs and menu navigation | High; automates complex multi-step resolutions across text, voice, and image |
| Escalation Intelligence | Blind handoff; human agent starts without context | Full context transferred to human agent including transcripts and images |
| Business Value | Deflects simple volume; limited ROI on complex cases | Deflects complex cases, reduces handle time, and improves CSAT across all channels |
| Maintenance | Requires frequent manual rule updates | Self-improving through Einstein model updates and conversation learning |
The Future of Multimodal AI in Salesforce
Agentforce multimodal and Salesforce multimodal AI are not endpoints — they are the beginning of a rapidly accelerating trajectory toward what Salesforce calls “digital labor”: AI agents that work autonomously alongside human employees, handling increasingly complex tasks across every business function.
The near-term roadmap points toward several significant expansions of multimodal capability:
Video Understanding — agents that can analyze video clips submitted by customers, enabling richer visual context for service interactions, remote inspections, and training scenarios.
Real-Time Translation — multimodal agents that instantly translate across languages in voice, text, and image contexts, enabling global organizations to serve customers in their native languages without dedicated multilingual support teams.
Proactive Multimodal Outreach — agents that don’t wait for customers to initiate contact, but proactively reach out through a customer’s preferred modality based on CRM triggers — sending a voice call to confirm a delivery, a text to flag an unusual account activity, or an image-based guide to assist with a known product issue.
Agentic Reasoning Across Modalities — more sophisticated orchestration where agents independently determine which modality to use for a given situation, switching between text, voice, and image not just based on what the customer submits, but on what will produce the most effective outcome.
As Salesforce’s AI platform continues to evolve, agentforce multimodal will become the standard for how organizations engage customers and empower employees — not a premium feature but a baseline expectation. Organizations that invest in multimodal AI infrastructure today will be positioned to deploy next-generation capabilities faster, with more accurate models and richer data foundations, than those starting from scratch.
Conclusion: One Agent, Every Modality, Unlimited Potential
The case for Agentforce Multimodal is straightforward: customers don’t think in channels, and neither should your AI. When a person needs help, they reach for whatever communication method is most natural in that moment — a typed message, a spoken question, a photo of what they’re looking at. Agentforce multimodal meets them there, in every modality, simultaneously, within one intelligent and context-aware agent.
Salesforce multimodal AI makes this possible by combining Einstein’s language understanding, real-time speech processing, and computer vision into one orchestrated platform grounded in live CRM data. And at the heart of the voice experience, the Agentforce Voice Agent delivers natural, human-like spoken interactions that eliminate the robotic frustration of traditional IVR systems.
For sales managers, service leaders, and IT architects, the implementation path is clear: configure Agentforce, connect your voice and image channels, define modality-specific prompts and actions, ground responses in CRM and Knowledge, and monitor performance by channel. The result is an AI agent that doesn’t just handle more interactions — it handles them better, faster, and with a level of understanding that single-channel systems simply cannot match.
The organizations leading in customer experience tomorrow are making their agentforce multimodal investments today. The technology is ready. The platform is proven. The only question is how quickly you choose to put it to work.
About RizeX Labs
At RizeX Labs, we specialize in delivering advanced Salesforce AI solutions that help businesses automate service, sales, and operational workflows using Agentforce and Einstein AI.
Our team combines deep Salesforce expertise, AI implementation experience, and real-world business knowledge to design intelligent agents that work across text, voice, and image channels.
We help organizations transform customer and employee interactions by deploying multimodal AI agents that can understand conversations, analyze uploaded images, and respond through natural voice experiences.
Internal Linking Opportunities
External Linking Opportunities
- Salesforce Agentforce
- Salesforce Artificial Intelligence Overview
- Salesforce Service Cloud Voice
- Salesforce Data Cloud
- Salesforce Help: Agentforce Documentation
Quick Summary
Agentforce Multimodal Agents bring together text, voice, and image capabilities into a single AI-powered assistant within Salesforce. Instead of deploying separate bots for chat, phone, and visual analysis, businesses can build one intelligent agent that understands customer intent across all communication channels.
With agentforce multimodal, organizations can automate conversations, process screenshots and photos, and deliver real-time voice interactions. Powered by salesforce multimodal AI, these agents improve service efficiency, reduce manual work, and create seamless customer experiences. The agentforce voice agent capability adds natural speech interactions, making AI-powered support feel more human and intuitive.
